在正式开始编写代码之前,我们还有一类复杂数据结构序列需要了解,序列(Sequence)是指按特定顺序依次排列的一组数据,它们可以占用一块连续的内存,也可以分散到多块内存中。序列类型包括列表(list)、元组(tuple)、字典(dict)和集合(set),序列类型都可以包含多个值,可以给我们处理大量数据带来巨大的便利,同时,序列结构本身都可以包含序列结构,因此,通过合理组织序列类型数据结构,有助于我们将数据安排成业务所需的层次结构。序列类型中的列表(list)和元组(tuple)比较相似,它们都按顺序保存元素,所有的元素占用一块连续的内存,每个元素都有自己的索引,因此列表和元组的元素都可以通过索引(index())来访问,它们的区别在于:列表是可以修改的,而元组是不可修改的。字典(dict)和集合(set)存储的数据都是无序的,每份元素占用不同的内存,其中字典元素以 key-value 的形式保存。
本章将首先讨论序列类型的概念及其支持的通用操作,然后探讨列表、元组、字典和集合的基础知识,讲解对应数据类型上的方法及方法的使用,然后介绍序列数据类型的使用技巧。
4.1 序列类型及其操作
所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引)访问它们。为了更形象的认识序列,可以将它看做是一列火车,那么火车中的每个车厢就如同序列存储数据的一个个内存空间,每个车厢所特有的编号就相当于索引值,前面介绍部分我们提到序列类型中可以包含序列类型,显然火车车厢中的每个座位就如同子序列存储数据的更细分的一个个小内存空间,每个座位唯一的编号就相当于子序列中索引值,也就是说,我们拿着票,进了站,通过车厢号(索引)我们可以找到这列火车(序列)中的我们的车厢(子序列),然后通过座位的编号(子序列索引),我们可以找到我们票上对应车厢中的座位。
在 Python 中,序列类型包括字符串、列表、元组、集合和字典,这些序列支持以下几种通用的操作,但比较特殊的是,集合和字典不支持索引、切片、相加和相乘操作。
字符串也是一种常见的序列,它也可以直接通过索引访问字符串内的字符,我们在上一章讲解的时候已经有了详细说明。
4.1.1 序列索引
序列中,每个元素都有属于自己的编号(索引)。从起始元素开始,索引值从 0 开始递增,Python还支持索引值是负数,此类索引是从右向左计数,换句话说,从最后一个元素开始计数,从索引值 -1 开始,如图4-1所示。

图 4-1 正向和逆向索引示意图
注意,在逆向索引使用负值作为列序中各元素的索引值时,是从-1开始,而不是从0开始。
无论是采用正向索引值,还是逆向索引值,都可以访问序列中的任何元素。以字符串为例,访问"Python教程"的首元素和倒数第二个尾元素,可以使用如下的代码:
>>> varStr="Python教程"
>>> varStr[0]
'P'
>>> varStr[-8]
'P'
>>> varStr[6]
'教'
>>> varStr[-2]
'教'
>>>
4.1.2 序列切片
切片操作是访问序列中元素的另一种方法,它可以访问一定范围内的元素,通过切片操作,可以生成一个新的序列,序列切片操作的语法格式如下:
varStr[start :end: step]
其中,各个参数的含义分别是:
varStr:表示序列的名称;
start:表示切片的开始索引位置(包括该位置),此参数也可以不指定,会默认从0开始,也就是从序列的开头进行切片;
end:表示切片的结束索引位置(不包括该位置),如果不指定,则默认为序列的长度,直接切到序列的尾部;
step:表示在切片过程中,每几个存储位置(包含当前位置)取一次元素,也就是说,如果step的值大于1,则在进行序列切片元时,以“跳跃”方式的取元素。如果省略设置step的值,则最后一个冒号就可以省略。
比如,对字符串"Python教程"进行切片:
>>> varStr="Python教程"
>>> varStr[:2]
'Py'
>>> varStr[:6]
'Python'
>>> varStr[:7]
'Python教'
>>> varStr[::3]
'Ph教'
>>> varStr[:]
'Python教程'
4.1.3 序列相加
Python支持多个类型相同的序列通过使用“+”运算符做连接操作,它会将多个序列进行连接,但不会去除重复的元素。这里所说的“类型相同”,指的是“+”运算符的两侧序列要么都是列表类型,要么都是元组类型,要么都是字符串。
例如,前面章节中我们已经实现用“+”运算符连接 2 个(甚至多个)字符串,如下所示:
>>> varStr="Python教程"
>>> url="inotemate.com"
>>> siteName="社区"
>>> url+siteName+varStr
'inotemate.com社区Python教程'
>>>
4.1.4 序列相乘
序列相乘并不是转换成数字得出数字结果,而是原来序列内容被重复乘以数字的次数,得到一个更长的序列。例如:
>>> url="inotemate.com"
>>> siteName="社区"
>>> url+siteName+varStr
'inotemate.com社区Python教程'
>>> (url+siteName+varStr)*4
'inotemate.com社区Python教程inotemate.com社区Python教程inotemate.com社区Python教程inotemate.com社区Python教程'
列表类型在使用乘法运算时,可以实现初始化指定长度列表的功能。
例如:创建一个长度为10的列表,列表中的每个元素都是0。
>>> varList=[0]
>>> newVarList=varList*10
>>> varList
[0]
>>> newVarList
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
4.1.5 检查元素是否包含在序列中
序列类型可以用 in关键字来检查某元素是否为序列的成员,其语法如下为:
item in seq
其中,item表示要检查的元素,seq表示被检查的序列。和in关键字用法相同,但功能刚好相反的,还有 not in关键字,它用来检查某个元素是否不包含在指定的序列中,例如,检查字符‘Python’是否包含在字符串'inotemate.com社区Python教程'中,示例代码:
>>> varStr="Python教程"
>>> 'Python' in varStr
True
>>> 'Python' not in varStr
False
4.1.6 序列相关的内置函数
Python提供了几个内置函数(表4-1所示),可用于实现与序列相关的一些常用操作。
表4-1序列相关的内置函数
|
函数 |
功能 |
|
len() |
计算序列的长度,即返回序列中包含多少个元素。 |
|
max() |
找出序列中的最大元素。 |
|
min() |
找出序列中的最小元素。 |
|
list() |
将序列转换为列表。 |
|
str() |
将序列转换为字符串。 |
|
sum() |
计算元素和。注意,对序列使用 sum() 函数时,做加和操作的必须都是数字,不能是字符或字符串,否则该函数将抛出异常,因为解释器无法判定是要做连接操作(+ 运算符可以连接两个序列),还是做加和操作。 |
|
sorted() |
对元素进行排序。 |
|
reversed() |
反向序列中的元素。 |
|
enumerate() |
将序列组合为一个索引序列,多用在 for 循环中。 |
下面给出函数使用的演示代码:
>>> varStr="Python教程"
>>> len(varStr)
8
>>> max(varStr)
'程'
>>> min(varStr)
'P'
>>> list(varStr)
['P', 'y', 't', 'h', 'o', 'n', '教', '程']
>>> str(list(varStr))
"['P', 'y', 't', 'h', 'o', 'n', '教', '程']"
>>> sorted(varStr)
['P', 'h', 'n', 'o', 't', 'y', '教', '程']
>>> reversed(varStr)
<reversed object at 0x7fb06a727c70> #倒序之后是迭代器,后面会讲到
>>> list(reversed(varStr)) #转成List就可以显示了,
['程', '教', 'n', 'o', 'h', 't', 'y', 'P']
>>> tuple(reversed(varStr)) #转成tuple也行
('程', '教', 'n', 'o', 'h', 't', 'y', 'P')
>>> set(reversed(varStr)) #转成Set也行,但是就看不错顺序了。
{'n', 'h', '教', 'o', 't', '程', 'y', 'P'}
>>> list(enumerate(varStr)) #就是给每个元素标个序号,可以转成List显示
[(0, 'P'), (1, 'y'), (2, 't'), (3, 'h'), (4, 'o'), (5, 'n'), (6, '教'), (7, '程')]
>>> dict(enumerate(varStr)) #可以转成字典显示
{0: 'P', 1: 'y', 2: 't', 3: 'h', 4: 'o', 5: 'n', 6: '教', 7: '程'}
>>> sum(varStr) #非数字不能求和
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'str'
>>> varInt=[1,4,6,3,8,99,24,68,3,67,536,7]
>>> sum(varInt) #对数字就可以求和
826
4.2 列表(List)
在实际开发中,经常需要将一组(不只一个)数据存储起来,以便后边的代码使用。说到这里,一些读者可能听说过数组(Array),它就可以把多个数据挨个存储到一起,通过数组下标可以访问数组中的每个元素。很不幸,Python 中没有数组类型,但提供了更加强大的列表类型。如果把数组看做是一个集装箱,那么Python的列表就可以看作是一个仓库。
从形式上看,列表会将所有元素都放在一对中括号[ ]里面,相邻元素之间用逗号,分隔,如下所示:
[item1 , item2 , item3 , item4, item5... , Itemn]
格式中,item1 ~ itemn表示列表元素,个数和类型都没限制,只要是 Python支持的数据类型就可以。
从内容上看,列表可以存储整数、小数、字符串、列表、元组等任何类型的数据,并且同一个列表中元素的类型也可以不同。比如说:
["http://inotemate.com/post/1", 45, [21,3.0,’abcd’] , 13.0]
注意,在使用列表时,虽然可以将不同类型的数据放入到同一个列表中,但为了提高程序的可理解性,最好同一列表中只存放同一类型的数据。
另外,我们也可以用list来代指列表,这是因为列表的数据类型就是list,可以通过type()函数来确定这一点,看代码:
>>> type(["http://inotemate.com/post/1", 45, [21,3.0,'abcd'], 13.0])
<class 'list'>
可以看到,它的数据类型就是list,就表示它是一个列表。
4.2.1 Python创建列表
在Python中,创建列表的方法有两种,一是直接赋值变量的方式,二是使用list()函数。
1、通过直接使用[ ]赋值方式
使用[ ]赋值创建列表,一般会使用=将它赋值给一个或多个变量,具体格式如下:
varList = [item1 , item2 , item3 , ... , Itemn]
其中,varList 表示变量名,item1 ~ itemn 表示列表元素。
例如,下面定义的列表都是合法的:
numInt = [1, 2, 3, 4, 5, 6, 7]
newNumInt=[1, 2, 3, 4, 5, 6, 7]
nameStr = ["iNoteMate社区", "http://inotemate.com"]
programStr = ["Rust语言", "Python", "JavaScript"]
使用直接赋值方式创建列表时,列表中元素可以有多个,也可以一个都没有,例如,[]里可以不包含值,创建一个空的列表:
emptyList = [ ]
2、使用list()函数从其他已有类型数据上创建列表
除了使用[ ]赋值方式创建列表外,Python还提供了一个内置的创建列表的函数list(),使用它可以将其它数据类型转换为列表类型。例如:
>>> varStr="Python教程"
>>> varList=list(varStr) #将字符串转换为List
>>> varList
['P', 'y', 't', 'h', 'o', 'n', '教', '程']
>>> varTuple=('P', 'y', 't', 'h', 'o', 'n', '教', '程')
>>> varTuple
('P', 'y', 't', 'h', 'o', 'n', '教', '程')
>>> list(varTuple) #将元组转换为List
['P', 'y', 't', 'h', 'o', 'n', '教', '程']
>>> varDict={0: 'P', 1: 'y', 2: 't', 3: 'h', 4: 'o', 5: 'n', 6: '教', 7: '程'}
>>> list(varDict) #将字典的item.key转换成List
[0, 1, 2, 3, 4, 5, 6, 7]
>>> list(range(0,10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(varDict.values()) #将字典的Item.values()转换成List
['P', 'y', 't', 'h', 'o', 'n', '教', '程']
>>> varSet=set(reversed(varStr))
>>> varSet
{'n', 'h', '教', 'o', 't', '程', 'y', 'P'}
>>> list(varSet) #将集合类型数据转成List
['n', 'h', '教', 'o', 't', '程', 'y', 'P']
4.2.2 访问列表元素
列表是Python序列的一种,我们可以使用索引(index())访问列表中的具体元素(得到的是一个元素的值),也可以使用切片访问列表中的一组元素(得到的是一个新的子列表)。
使用索引访问列表元素的语法为:
varList[i]
其中,varList表示列表名字,i表示索引值。列表的索引可以是正数,也可以是负数。
使用切片访问列表元素的语法为:
varList[start :end: step]
其中,varList表示列表名字,start 表示起始索引,end 表示结束索引,step 表示步长。
以上两种方式我们已在4.1中进行了讲解,这里就不再赘述了,仅作示例演示,请看下面代码:
>>> urlList=list('http://inotemate.com/user/iNoteMateAdmin')
>>> urlList[8]
'n'
>>> urlList[-11]
't'
>>> urlList[2:19:3]
['t', '/', 'n', 'e', 't', 'c']
>>> urlList[2:19]
['t', 'p', ':', '/', '/', 'i', 'n', 'o', 't', 'e', 'm', 'a', 't', 'e', '.', 'c', 'o']
>>> urlList[-1:-6]
[]
>>> urlList[-18:-6]
['s', 'e', 'r', '/', 'i', 'N', 'o', 't', 'e', 'M', 'a', 't']
>>> urlList[-18:-6:3]
['s', '/', 'o', 'M']
4.2.3 删除列表
对于已经创建的列表,如果不再使用,可以使用del关键字将其删除。实际开发中并不经常使用del来删除列表,因为Python自带的垃圾回收机制会自动销毁无用的列表,即使开发者不手动删除,Python也会自动将其回收。
del的作用不仅仅是删除列表,可以删除任意已创建的变量,其语法格式为:
del varName
其中,varName表示要删除变量的名称,我们在上一章演示过其删除其他类型变量的使用,这里我们演示一下删除列表变量,代码如下:。
>>> urlList=list('http://inotemate.com/user/iNoteMateAdmin')
>>> urlList
['h', 't', 't', 'p', ':', '/', '/', 'i', 'n', 'o', 't', 'e', 'm', 'a', 't', 'e', '.', 'c', 'o', 'm', '/', 'u', 's', 'e', 'r', '/', 'i', 'N', 'o', 't', 'e', 'M', 'a', 't', 'e', 'A', 'd', 'm', 'i', 'n']
>>> del urlList
>>> urlList
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'urlList' is not defined
4.2.4 列表内数据的增删改查
实际开发中,经常需要对 Python 列表进行更新,包括向列表中添加元素、修改列表中的元素、删除元素和查询有没有指定的元素,本小节就一一详细介绍,先从向列表中添加元素开始。
1、Pythonlist列表添加元素的3种方法
4.1序列一节已经告诉我们,使用+运算符可以将多个序列连接起来;列表是序列的一种,所以也可以使用+进行连接,这样就相当于在第一个列表的末尾添加了另一个列表,请看下面的代码:
>>> programList = ["Rust", "Python", "JavaScript"]
>>> personList = ["Graydon Hoare", "Guido van Rossum", "Brendan Eich"]
>>> yearList=[2006,1990,1995]
>>> languageList=programList+personList+yearList
>>> rustList=languageList[::3]
>>> PythonList=languageList[1::3]
>>> javaScriptList=languageList[2::3]
>>> rustList
['Rust', 'Graydon Hoare', 2006]
>>> PythonList
['Python', 'Guido van Rossum', 1990]
>>> javaScriptList
['JavaScript', 'Brendan Eich', 1995]
>>> programList
['Rust', 'Python', 'JavaScript']
>>> personList
['Graydon Hoare', 'Guido van Rossum', 'Brendan Eich']
>>> yearList
[2006, 1990, 1995]
>>> languageList
['Rust', 'Python', 'JavaScript', 'Graydon Hoare', 'Guido van Rossum', 'Brendan Eich', 2006, 1990, 1995]
从运行结果可以发现,使用+运算符会生成一个新的列表,原有的列表内容不会改变。+运算符更多的是用来拼接列表,而且执行效率并不高,如果想在列表中插入元素,应该使用下面几个专门的方法。
A、append()方法添加元素
append()方法用于在列表的末尾追加元素,该方法的语法格式如下:
varvarNameList.append(obj)
其中,varvarNameList表示要添加元素的列表变量;obj 表示到添加到列表末尾的数据,它可以是单个元素,也可以是列表、元组、字典和集合等。append()的使用细节请看如下代码:
>>> programList = ["Rust", "Python", "JavaScript"]#追加元素
>>> programList.append('Dart')#追加元素
>>> programList
['Rust', 'Python', 'JavaScript', 'Dart']
>>> msNetTuple = ('C++.net', 'C#', 'vb.net')
>>> programList.append(msNet)
>>> programList
['Rust', 'Python', 'JavaScript', 'Dart', ('C++.net', 'C#', 'vb.net')]
>>> borlandList=['Delphi', 'Kylix']
>>> programList.append(borlandList)
>>> programList
['Rust', 'Python', 'JavaScript', 'Dart', ('C++.net', 'C#', 'vb.net'), ['Delphi', 'Kylix']]
可以看到,当给append()方法传递列表或者元组时,此方法会将它们视为一个整体,作为一个元素添加到列表中,从而形成包含列表和元组的新列表。
B、extend()方法添加元素
extend()和append()的不同之处在于:extend()不会把列表或者元祖视为一个整体,而是把它们包含的元素逐个添加到列表中。
extend() 方法的语法格式如下:
varNameList.extend(obj)
其中,varNameList指的是要添加元素的列表;obj 表示到添加到列表末尾的数据,它可以是单个元素,也可以是列表、元组等,但不能是单个的数字。
>>> programList = ["Rust", "Python", "JavaScript"]
>>> programList.extend('Dart')
>>> programList
['Rust', 'Python', 'JavaScript', 'D', 'a', 'r', 't'] #extend会将序列中元素一个个添加
>>> programList = ["Rust", "Python", "JavaScript"]
>>> dartStr=['Dart'] #想整体添加,必须定义称一个整体
>>> programList.extend(dartStr)
>>> programList
['Rust', 'Python', 'JavaScript', 'Dart']
>>> programList = ["Rust", "Python", "JavaScript"]
>>> varTuple = ('C++.net', 'C#', 'vb.net')
>>> programList.extend(varTuple)
>>> programList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net'] #把元组中元素一个一个添加
>>> borlandList=['Delphi', 'Kylix']
>>> programList.extend(borlandList) #将列表中的元素拆分一个个加如序列
>>> programList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> programList.extend('Dart')
>>> programList # 将字符串看成序列,拆开一个个元素添加到列表
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix', 'D', 'a', 'r', 't']
>>> programList.extend(5) #不能添加数字,因为数字不可迭代
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
>>> programList.extend([5]) #想加数字,以列表形式提供
>>> programList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix', 'D', 'a', 'r', 't', 5]
>>> programList.extend((6)) #不能添加单一元素的元组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
>>> programList.extend((6,7))
>>> programList.extend((6,)) #如果是单一元素,必须以这种形式
>>> programList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix', 'D', 'a', 'r', 't', 5, 6, 7, 6]
>>> programList.extend({6}) #可以以集合形式提供
>>> programList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix', 'D', 'a', 'r', 't', 5, 6, 7, 6, 6]
C、insert()方法插入元素
append()和extend()方法只能在列表末尾插入元素,如果希望在列表中间的某个位置插入元素,那么可以使用 insert() 方法。insert() 的语法格式如下:
varNameList.insert(index(), obj)
其中,index()表示指定位置的索引值。insert() 会将obj插入到varNameList列表第index()个元素的位置。插入列表、元组、字典或集合时,insert()也会将它们视为一个整体,作为一个元素插入到列表中,这一点和append()是一样的。看代码:
>>> programList = ["Rust", "Python", "JavaScript"]
>>> programList.insert(2,"Dart") #不会像extend一样拆开,而是作为一个整体
>>> programList
['Rust', 'Python', 'Dart', 'JavaScript']
>>> programList.insert(2,3) #可以插入任意类型元素,数字
>>> programList
['Rust', 'Python', 3, 'Dart', 'JavaScript']
>>> borlandList=['Delphi', 'Kylix'] #插入子列表
>>> programList.insert(2,borlandList)
>>> programList
['Rust', 'Python', ['Delphi', 'Kylix'], 3, 'Dart', 'JavaScript']
>>> varTuple = ('C++.net', 'C#', 'vb.net') #插入元组
>>> programList.insert(2,varTuple)
>>> programList
['Rust', 'Python', ('C++.net', 'C#', 'vb.net'), ['Delphi', 'Kylix'], 3, 'Dart', 'JavaScript']
>>> varSet=set(reversed(varStr))
>>> varStr="Python教程"
>>> varSet=set(reversed(varStr))
>>> varSet
{'n', 'h', '教', 'o', 't', '程', 'y', 'P'}
>>> programList.insert(2,varSet) #插入集合
>>> programList
['Rust', 'Python', {'n', 'h', '教', 'o', 't', '程', 'y', 'P'}, ('C++.net', 'C#', 'vb.net'), ['Delphi', 'Kylix'], 3, 'Dart', 'JavaScript']
>>> varDict=dict(enumerate(varStr))
>>> varDict
{0: 'P', 1: 'y', 2: 't', 3: 'h', 4: 'o', 5: 'n', 6: '教', 7: '程'}
>>> programList.insert(2,varDict) #插入字典
>>> programList
['Rust', 'Python', {0: 'P', 1: 'y', 2: 't', 3: 'h', 4: 'o', 5: 'n', 6: '教', 7: '程'}, {'n', 'h', '教', 'o', 't', '程', 'y', 'P'}, ('C++.net', 'C#', 'vb.net'), ['Delphi', 'Kylix'], 3, 'Dart', 'JavaScript']
insert()主要用来在列表的中间位置插入元素,如果你仅仅希望在列表的末尾追加元素,那我更建议使用append()或extend()。
2、列表删除元素
在 Python 列表中删除元素主要分为以下 3 种场景:
根据目标元素的索引进行删除,可以使用del关键字或者pop()方法;
根据元素的值进行删除,可使用列表(list类型)提供的remove()方法;
删除列表全部元素,可使用列表(list类型)提供的 clear()方法。
A、del:根据索引值删除元素
del是Python中的关键字,专门用来执行删除操作,它不仅可以删除整个列表,还可以删除列表中的某些元素。我们已经在4.1节中讲解了如何删除整个列表,所以本节只讲解如何删除列表元素。del可以删除列表中的单个元素,其语法格式为:
del varNameList[index()]
其中,varNameList表示列表名称,index()表示元素的索引值。
del也可以step为步长,切片删除了列表中间的元素,语法格式为:
del varNameList[start: end: step]
其中,start:表示删除的开始索引位置(包括该位置),此参数也可以不指定,会默认从0开始,也就是从序列的开头进行切片删除;
end:表示删除的结束索引位置(不包括该位置),如果不指定,则默认为序列的长度,直接切片删除序列的尾部;
step:表示在切片过程中,每几个存储位置(包含当前位置)删除一个元素,也就是说,如果step的值大于1,则在进行序列删除元素时,以“跳跃”方式进行。如果省略设置step的值,默认就是1,则表示连续删除,则最后一个冒号就可以省略。
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> del langList[4] #删除单元素 正向索引
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'vb.net', 'Delphi', 'Kylix']
>>> del langList[-4] #删除单元素 逆向索引
>>> langList
['Rust', 'Python', 'JavaScript', 'vb.net', 'Delphi', 'Kylix']
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> del langList[2:5] #删除连续元素 正向索引 默认step为1
>>> langList
['Rust', 'Python', 'vb.net', 'Delphi', 'Kylix']
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> del langList[2:-2] #删除连续元素 正逆向混合用 默认step为1
>>> langList
['Rust', 'Python', 'Delphi', 'Kylix']
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> del langList[-8:-3] #删除连续元素 逆向索引 默认step为1
>>> langList
['vb.net', 'Delphi', 'Kylix']
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> del langList[2::2] #间隔删除 正向索引 每隔两个元素
>>> langList
['Rust', 'Python', 'C++.net', 'vb.net', 'Kylix']
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> del langList[:-3:2] #间隔删除 逆向索引 每隔两个元素
>>> langList
['Python', 'C++.net', 'vb.net', 'Delphi', 'Kylix']
B、pop():根据索引值删除元素
pop()方法是用来删除列表中指定索引处的元素,具体语法格式如下:
varNameList.pop(index())
其中,varNameList表示列表变量名称,index()表示索引值。如果不写index()参数,默认删除列表最后一个元素,类似于堆栈的“出栈”操作。示例代码如下:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList.pop(3)
'C++.net'
>>> langList
['Rust', 'Python', 'JavaScript', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList.pop()
'Kylix'
>>> langList
['Rust', 'Python', 'JavaScript', 'C#', 'vb.net', 'Delphi']
大部分编程语言都会提供和pop()函数对应的方法,一般是push(),该方法用来将元素添加到列表变量的尾部,类似于堆栈的“入栈”操作。但是Python没有提供push()方法,而是使用 append()来实现push()的功能。
C、remove():根据元素值进行删除
前面将的del关键字是按索引进行删除,如果删除指定值的元素呢?为了实现这个操作Python提供了remove() 方法,该方法会根据元素本身的值来进行删除操作。需要注意的是,remove()方法只会删除第一个和指定值相同的元素,而且必须保证该元素是存在的,否则会引发 ValueError 错误。看示例代码:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList.remove('C#')
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'vb.net', 'Delphi', 'Kylix']
>>> langList.remove('C#')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: list.remove(x): x not in list
当第二次在删除'C#'时,因为'C#'不存在导致报错,所以我们在使用remove() 删除元素时最好提前判断一下。
D、clear():删除列表所有元素
Pythonclear() 用来删除列表的所有元素,也即清空列表,请看下面的代码:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList.clear()
>>> langList
[]
3、列表修改元素
Python 有两种修改列表(list)元素的方法,你可以每次修改单个元素,也可以每次修改一组元素(多个)。
A、修改单个元素
修改单个元素非常简单,直接对元素赋值即可。请看下面的例子:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList[3]="VBScript"
>>> langList
['Rust', 'Python', 'JavaScript', 'VBScript', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList[-3]='.Net'
>>> langList
['Rust', 'Python', 'JavaScript', 'VBScript', 'C#', '.Net', 'Delphi', 'Kylix']
使用索引得到列表元素后,通过=赋值就改变了元素的值。
B、修改一组元素
Python还可以通过切片语法给一组元素赋值。在进行这种操作时,如果不指定步长(step 参数),Python就不要求新赋值的元素个数与原来的元素个数相等;这意味,该操作既可以为列表添加元素,也可以从列表删除元素。看代码:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList[3:6]=['Pascal','SQL','Shell','PHP','Perl'] #从索引3开始
>>> langList
['Rust', 'Python', 'JavaScript', 'Pascal', 'SQL', 'Shell', 'PHP', 'Perl', 'Delphi', 'Kylix']
如果对空切片赋值,就相当于插入一组新的元素:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList[6:6]=['Pascal','SQL','Shell','PHP','Perl']
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Pascal', 'SQL', 'Shell', 'PHP', 'Perl', 'Delphi', 'Kylix']
使用切片语法赋值时,Python不支持直接赋予数字单个值,如确需赋入单个数字,请以列表或者可迭代的元组形式给出,看下面代码:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList[5:5]=77 #不能直接赋予数值
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only assign an iterable
>>> langList[5:5]=[77] #可以通过列表形式赋予
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 77, 'vb.net', 'Delphi', 'Kylix']
>>> langList[5:5]=(88) #单个元组形式也不行,不能迭代
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only assign an iterable
>>> langList[5:5]=(88,) #以迭代方式给出就可以
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 88, 77, 'vb.net', 'Delphi', 'Kylix']
但是如果使用字符串赋值,Python会自动把字符串转换成序列,其中的每个字符都是一个元素,请看下面的代码:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList[2:5]="Fortran"
>>> langList #我们本意是加入"Fortran",但被拆分成字母了
['Rust', 'Python', 'F', 'o', 'r', 't', 'r', 'a', 'n', 'vb.net', 'Delphi', 'Kylix']
使用切片语法修改时,也可以指定步长(step 参数),但这个时候就要求所赋值的新元素的个数与原有元素的个数相同,看代码:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList[1:7:2]=['Pascal','SQL','Shell','PHP'] #实际修改的数量是3,我们提供4个值
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: attempt to assign sequence of size 4 to extended slice of size 3
>>> langList[1:7:2]=['Pascal','SQL','Shell'] #赋值新元素个数与原元素个数相同
>>> langList
['Rust', 'Pascal', 'JavaScript', 'SQL', 'C#', 'Shell', 'Delphi', 'Kylix']
4、列表查找元素
列表提供了index()和count()方法用以查找元素。
A、index()方法
index()方法用来查找某个元素在列表中出现的位置(也就是索引),如果该元素不存在,则会导致 ValueError 错误,所以在查找之前最好使用count()方法判断一下。index()的语法格式为:
varNameList.index(obj, start, end)
其中varNameList表示列表名称,obj 表示要查找的元素,start 表示起始位置,end 表示结束位置。start 和end参数用来指定检索范围:
- start和end可以都不写,会检索整个列表;
- 如果只写start不写end,表示检索从start到末尾的元素;
- 如果start和end都写,那么表示检索start和end之间的元素。
index()方法会返回元素所在列表中的索引值,看代码:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList
['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langList.index("C#")
4
>>> langList.index("C++.net",2,6)
3
>>> langList.index("C++.net",2)
3
>>> langList.index("Delphi",5)
6
>>> langList.index("Ruby",5)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 'Ruby' is not in list
>>> langList.index("Ruby")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 'Ruby' is not in list
B、count()方法
count()方法用来统计某个元素在列表中出现的次数,基本语法格式为:
varNameList.count(obj)
其中,varNameList代表列表名,obj表示要统计的元素。如果count()返回 0,说明列表中不存在该元素,所以count()也可以用来判断列表中的某个元素是否存在。看代码:
>>> langList=['Rust', 'Python', 'JavaScript', 'C++', 'C#', 'vb.net', 'Delphi', 'Kylix','C#','Python','C#','Java','PHP']
>>> langList
['Rust', 'Python', 'JavaScript', 'C++', 'C#', 'vb.net', 'Delphi', 'Kylix', 'C#', 'Python', 'C#', 'Java', 'PHP']
>>> langList.count('C#')
3
>>> langList.count('Ruby')
0
4.3 元组(Tuple)
元组(tuple)另一个重要的序列结构,和列表类似,元组也是由一系列按特定顺序排序的元素组成。元组和列表(list)的不同之处在于:
- 列表的元素是可以更改的,包括修改元素值,删除和插入元素,所以列表是可变序列;
- 而元组一旦被创建,它的元素就不可更改了,所以元组是不可变序列。
元组可以看做不变的列表,写程序的时候,元组用于保存无需修改的数据。从形式上看,元组的所有元素都放在一对小括号( )中,相邻元素之间用逗号,分隔,如下所示:
(item1, item2, ... , itemn)
其中item1~itemn表示元组中的各个元素,个数和元素内容都没有限制,只要是Python支持的数据类型就可以。元组可以存储整数、实数、字符串、列表、元组、字典、集合等任何类型的数据,并且在同一个元组中,元素的类型可以不同,例如:
("inotemate.com", 10,"iNoteMate社区",{2,'34'},{ 'name':'oliver','age':25},[2,'a'], ("abc",3.0))
在这个元组中,有多种类型的数据:整型、字符串、列表、元组、集合、字典等等。另外,我们都知道,列表的数据类型是 list,那么元组的数据类型是什么呢?我们不妨通过 type() 函数来查看一下:
>>> varTuple=("inotemate.com", 10,"iNoteMate社区",{2,'34'},{ 'name':'oliver','age':25},[2,'a'], ("abc",3.0))
>>> type(varTuple)
<class 'tuple'>
可以看到,元组是tuple类型,我们后面也会用到tuple来指代元组。
4.3.1 创建元组
Python提供了两种创建元组的方法,下面一一进行介绍。
1、使用( )直接创建
通过( )创建元组后,使用=将其赋值给具体的变量,语法格式为:
varNameTuple = (item1, item2, ..., itemn)
其中,varNameTuple表示变量名,item1 ~ itemn 表示元组的元素。
varNameTuple=("inotemate.com", 10,"iNoteMate社区",{2,'34'},{ 'name':'oliver','age':25} [2,'a'], ("abc",3.0))
numTuple = (33, 22.3, 3.56, 1.28, 35)
courseTuple = ("iNoteMate社区", "http://inotemate.com/post/24")
在Python中,元组通常都是使用一对小括号将所有元素包围起来的,但小括号不是必须的,只要将各元素用逗号隔开,Python就会将其视为元组,看下面例子:
>>> varNameTuple="inotemate.com", 10,"iNoteMate社区",{2,'34'},{ 'name':'oliver','age':25},[2,'a'], ("abc",3.0)
>>> varNameTuple
('inotemate.com', 10, 'iNoteMate社区', {'34', 2}, {'name': 'oliver', 'age': 25}, [2, 'a'], ('abc', 3.0))
>>> type(varNameTuple)
<class 'tuple'>
需要注意的是,当创建的元组中只有一个元素时,该元素后面必须要加一个逗号,,否则Python解释器会将它视为元素本身类型。看代码:
>>> varNumTuple=(6)
>>> type(varNumTuple) #没有‘,’号,还是视为整数
<class 'int'>
>>> varNumTuple=(6,) #有了‘,’号,视为元组
>>> type(varNumTuple)
<class 'tuple'>
>>> varStrTuple=("http://inotemate.com/post/24") #没有‘,’号,还是视为字符串
>>> type(varStrTuple)
<class 'str'>
>>> varStrTuple=("http://inotemate.com/post/24",)#有了‘,’号,视为元组
>>> type(varStrTuple)
<class 'tuple'>
2、用tuple()函数创建元组
除了使用( )创建元组外,Python还提供了一个内置的函数tuple(),用来将其它数据类型转换为元组类型。tuple() 的语法格式如下:
tuple(obj)
其中,obj表示可以转化为元组的数据,包括字符串、元组、range 对象等。
看示例代码:
>>> str="http://inotemate.com/post/24"
>>> strTuple=tuple(str) #将字符串转换为元组
>>> strTuple
('h', 't', 't', 'p', ':', '/', '/', 'i', 'n', 'o', 't', 'e', 'm', 'a', 't', 'e', '.', 'c', 'o', 'm', '/', 'p', 'o', 's', 't', '/', '2', '4')
>>> langList=['Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix']
>>> langTuple=tuple(langList) #将列表转为元组
>>> langTuple
('Rust', 'Python', 'JavaScript', 'C++.net', 'C#', 'vb.net', 'Delphi', 'Kylix')
>>> itemDict={'name':'oliver','age':'34'}
>>> itemDict
{'name': 'oliver', 'age': '34'}
>>> itemType=tuple(itemDict) #将字典的Key转为元组
>>> itemType
('name', 'age')
>>> keysTuple=tuple(itemDict.keys()) #将字典的Key转为元组
>>> keysTuple
('name', 'age')
>>> valueTuple=tuple(itemDict.values()) #将字典的values转为元组
>>> valueTuple
('oliver', '34')
>>> varSet={'asd','bdd',4}
>>> varSet
{'asd', 4, 'bdd'}
>>> varTuple=tuple(varSet) #将集合转为元组
>>> varTuple
('asd', 4, 'bdd')
>>> rangeInt=range(0,10)
>>> rangeInt
range(0, 10)
>>> rangeTuple=tuple(rangeInt) #将范围数转为元组
>>> rangeTuple
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
>>> tuple() #创建空元组
()
4.3.2 Python访问元组元素
元组是序列的一种,我们也可以使用索引(Index)访问元组中的某个元素(得到的是一个元素的值),也可以使用切片访问元组中的一组元素(得到的是一个新的子元组)。使用索引访问元组元素的语法格式为:
varNameTuple[index]
其中,varNameTuple表示元组变量名字,index表示索引值。元组的索引可以是正数,也可以是负数。
以切片方式访问元组元素的语法格式为:
varNameTuple[start : end : step]
其中,start表示起始索引,end表示结束索引,step表示步长。
以上两种方式我们已在4.1节中进行了讲解,这里就不再赘述了,仅作示例演示,请看下面代码:
>>> urlTuple= tuple("http://inotemate.com/post/24")
>>> urlTuple
('h', 't', 't', 'p', ':', '/', '/', 'i', 'n', 'o', 't', 'e', 'm', 'a', 't', 'e', '.', 'c', 'o', 'm', '/', 'p', 'o', 's', 't', '/', '2', '4')
>>> urlTuple[10]
't'
>>> urlTuple[-4]
't'
>>> urlTuple[2:20]
('t', 'p', ':', '/', '/', 'i', 'n', 'o', 't', 'e', 'm', 'a', 't', 'e', '.', 'c', 'o', 'm')
>>> urlTuple[2:20:4]
('t', '/', 't', 't', 'o')
>>> urlTuple[2:20:3]
('t', '/', 'n', 'e', 't', 'c')
>>> urlTuple[2:20:5]
('t', 'i', 'm', 'c')
>>> urlTuple[2:-5:5]
('t', 'i', 'm', 'c', 'o')
>>> urlTuple[-20:-3:2]
('n', 't', 'm', 't', '.', 'o', '/', 'o', 't')
>>> urlTuple[-20:-3]
('n', 'o', 't', 'e', 'm', 'a', 't', 'e', '.', 'c', 'o', 'm', '/', 'p', 'o', 's', 't')
4.3.3 Python修改元组
前面我们已经说过,元组是不可变序列,元组中的元素不能被修改,所以我们只能创建一个新的元组去替代旧的元组。看代码:
>>> varTuple=("inotemate.com", 10,"iNoteMate社区",{2,'34'})
>>> varTuple
('inotemate.com', 10, 'iNoteMate社区', {'34', 2})
>>> varTuple=({ 'name':'oliver','age':25} ,[2,'a'], ("abc",3.0))
>>> varTuple
({'name': 'oliver', 'age': 25}, [2, 'a'], ('abc', 3.0))
>>>
另外,还可以通过连接多个元组(使用+可以拼接元组)的方式向元组中添加新元素,例如:
>>> varTuple1=("inotemate.com", 10,"iNoteMate社区",{2,'34'})
>>> varTuple2=({ 'name':'oliver','age':25} ,[2,'a'], ("abc",3.0))
>>> varTuple1+varTuple2
('inotemate.com', 10, 'iNoteMate社区', {'34', 2}, {'name': 'oliver', 'age': 25}, [2, 'a'], ('abc', 3.0))
>>> varTuple1
('inotemate.com', 10, 'iNoteMate社区', {'34', 2})
>>> varTuple2
({'name': 'oliver', 'age': 25}, [2, 'a'], ('abc', 3.0))
你看,使用+拼接元组以后,varTuple1和varTuple2的内容没法发生改变,但连接会生成一个新的元组。
4.3.4 Python删除元组
当你在代码中创建的元组不再使用时,可以通过del关键字将其删除,例如:
>>> varTuple1=("inotemate.com", 10,"iNoteMate社区",{2,'34'})
>>> varTuple2=({ 'name':'oliver','age':25} ,[2,'a'], ("abc",3.0))
>>> newVarTuple=varTuple1+varTuple2
>>> newVarTuple
('inotemate.com', 10, 'iNoteMate社区', {'34', 2}, {'name': 'oliver', 'age': 25}, [2, 'a'], ('abc', 3.0))
>>> del newVarTuple
>>> newVarTuple
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'newVarTuple' is not defined
>>> varTuple1
('inotemate.com', 10, 'iNoteMate社区', {'34', 2})
>>> varTuple2
({'name': 'oliver', 'age': 25}, [2, 'a'], ('abc', 3.0))
删除newVarTuple显然对原始的两个元组每影响,Python自带垃圾回收功能,会自动销毁不用的元组,所以一般不需要通过 del 来手动删除。
4.4 字典(Dict)
字典(dict)是一种无序的、可变的序列,它的元素以“key:value”的形式存储。前面学的列表(list)和元组(tuple)都是有序的序列,它们的元素在底层是挨着存放的。
字典类型是Python中唯一的映射类型,即通过一个key,只能唯一找到另一个value。如图4-2所示。

图4-2 映射关系示意图
在字典中,习惯将各元素对应的索引称为键(key),各个键对应的元素称为值(value),键及其关联的值称为“键值对”。字典的每个键值对用冒号:分割,每个对之间用逗号(,)分割,整个字典包括在花括号{}中
总的来说,字典类型所具有的主要特征如表4-2所示。
表4-2Python字典特征
|
主要特征 |
解释 |
|
用键而不是用索引来读取元素 |
字典类型也称为关联数组或者散列表(hash)。它用键将一系列的值联系起来,通过键从字典中获取指定项,但不能通过索引来获取。 |
|
字典是任意数据类型的无序集合 |
列表、元组通常会将索引值0对应的元素称为第一个元素,而字典中的元素是无序的。 |
|
字典是可变的,可以任意嵌套 |
字典可以在原处增长或者缩短(无需生成一个副本),并且它支持任意深度的嵌套,即字典存储的值可以是任意数据类型或其它的字典。 |
|
键必须唯一 |
字典中,不支持同一个键多次出现,否则只会保留最后一个键值对。 |
|
键必须不可变 |
字典中每个键值对的键是不可变的,只能使用数字、字符串或者元组,不能使用列表。 |
Python中的字典类型相当于 Java 或者 C++ 中的 Map 对象。
和列表、元组一样,字典也有它自己的类型。Python中,字典的数据类型为 dict,通过 type() 函数即可查看:
>>> varNameDict={'id':'51702042005','name':'张三','birthday':'2002-12-14','gender':'male','address':'安徽蚌埠'}
>>> type(varNameDict)
<class 'dict'>
4.4.1 Python创建字典
创建字典的方式有很多,下面一一做介绍。
1、 使用{ }创建字典
由于字典中每个元素都包含两部分,分别是键(key)和值(value),因此在创建字典时,键和值之间使用冒号:分隔,相邻元素之间使用逗号,分隔,所有元素放在大括号{ }中。使用{ }创建字典的语法格式如下:
varNameDict = {'key':'value1', 'key2':'value2', ..., 'keyn':valuen}
其中 varNameDict 表示字典变量名,keyn : valuen 表示各个元素的键值对。需要注意的是,同一字典中的各个键必须唯一,不能重复。
如下代码示范了如何使用花括号语法创建字典:
>>> varNameDict={'id':'51702042005','name':'张三','birthday':'2002-12-14','gender':'male','address':'安徽蚌埠'} #字符串做Key
>>> scoresDict = {'id':'51702042005','高等数学1': 95, '大学英语1': 92, 'C语言': 84,'哲学':'78'} #字符串做Key
>>> scoresDict
{'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78'}
>>> varDict={('第一名','第二名','第三名'):'一等奖',('第四名','第十名'):'二等奖',('其余'):'三等奖'}
>>> varDict #元组做Key
{('第一名', '第二名', '第三名'): '一等奖', ('第四名', '第十名'): '二等奖', '其余': '三等奖'}
>>> tuppleKeyDict={('第一名','第二名','第三名'):'一等奖',('第四名','第十名'):'二等奖',('其余'):'三等奖'}
>>> listKeyDict={['第一名','第二名','第三名']:'一等奖',['第四名','第十名']:'二等奖',['其余']:'三等奖'} #列表因为是可变的,所有不能做Key
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> gradeDict={'一等奖':range(1,4),'二等奖':range(4,11),'三等奖':range(11,21),' 优秀奖':range(21,61)}
>>> gradeDict
{'一等奖': range(1, 4), '二等奖': range(4, 11), '三等奖': range(11, 21), '优秀奖': range(21, 61)}
>>> gradeDict={1:range(1,4),2:range(4,11),5:range(11,21),0:range(21,61)}
>>> gradeDict #数字做Key
{1: range(1, 4), 2: range(4, 11), 5: range(11, 21), 0: range(21, 61)}
可以看到,字典的key可以是整数、字符串或者元组,只要符合唯一和不可变的特性就行;字典的值可以是Python支持的任意数据类型。
2、通过 fromkeys() 方法创建字典
使用dict字典类型提供的fromkeys()方法创建带有默认值的字典,语法如下:
varNameDict = dict.fromkeys(list,value=None)
其中,list参数表示字典中所有键,list的类型可以是列表、元组、字符串和range;value参数表示默认值,如果不写,则为空值None。看代码:
>>> gradeList=['一等奖','二等奖','三等奖','优秀奖']
>>> gradeDict=dict.fromkeys(gradeList,None) #Key从列表中取
>>> gradeDict
{'一等奖': None, '二等奖': None, '三等奖': None, '优秀奖': None}
>>> gradeTuple=('一等奖','二等奖','三等奖','优秀奖')
>>> gradeDict=dict.fromkeys(gradeTuple,None) #key从元组中获取
>>> gradeDict
{'一等奖': None, '二等奖': None, '三等奖': None, '优秀奖': None}
>>> gradeDict=dict.fromkeys("字符串做Key",None) #key用字符串生成
>>> gradeDict
{'字': None, '符': None, '串': None, '做': None, 'K': None, 'e': None, 'y': None}
>>> gradeDict=dict.fromkeys(range(0,11),None) #Key使用range生成
>>> gradeDict
{0: None, 1: None, 2: None, 3: None, 4: None, 5: None, 6: None, 7: None, 8: None, 9: None, 10: None}
可以看到,gradeDict字典的key可以通过能转换成迭代类型的数据生成,这种创建方式通常用于初始化字典。
3、通过dict()映射函数创建字典
通过dict()函数创建字典的写法有多种。
- 可以通过直接赋str=value的形式创建,str=表示字符串类型的键,value 表示键对应的值。使用此方式创建字典时,字符串不能带引号。
>>> varNameDict=dict(urlStr="inotemate.com", userCount=10,urlAlais=("iNoteMate社区","iNoteMate CMS"),extraInfo={2,'34'})
>>> varNameDict
{'urlStr': 'inotemate.com', 'userCount': 10, 'urlAlais': ('iNoteMate社区', 'iNoteMate CMS'), 'extraInfo': {'34', 2}}
- 向dict()函数传入列表或元组,而它们中的元素又各自是包含 2 个元素的列表或元组,其中第一个元素作为键,第二个元素作为值。
#方式1 外列表内元组
>>> varDict4=[('urlName','inotemate.com'),('userCount',10),('urlAlais','iNoteMate社区')]
>>> varDict4
[('urlName', 'inotemate.com'), ('userCount', 10), ('urlAlais', 'iNoteMate社区')]
>>> varDict4=dict(varDict4)
>>> varDict4
{'urlName': 'inotemate.com', 'userCount': 10, 'urlAlais': 'iNoteMate社区'}
#方式2 内外均列表
>>> varDict2=[['urlName','inotemate.com'],['userCount',10],['urlAlais','iNoteMate社区']]
>>> varDict2
[['urlName', 'inotemate.com'], ['userCount', 10], ['urlAlais', 'iNoteMate社区']]
>>> varDict2=dict(varDict2)
>>> varDict2
{'urlName': 'inotemate.com', 'userCount': 10, 'urlAlais': 'iNoteMate社区'}
#方式3 内外均元组
>>> varDict1=(('urlName','inotemate.com'),('userCount',10),('urlAlais','iNoteMate社区'))
>>> varDict1
(('urlName', 'inotemate.com'), ('userCount', 10), ('urlAlais', 'iNoteMate社区'))
>>> varDict1=dict(varDict1)
>>> varDict1
{'urlName': 'inotemate.com', 'userCount': 10, 'urlAlais': 'iNoteMate社区'}
#方式4 外元组内列表
>>> varDict3=(['urlName','inotemate.com'],['userCount',10],['urlAlais','iNoteMate社区'])
>>> varDict3
(['urlName', 'inotemate.com'], ['userCount', 10], ['urlAlais', 'iNoteMate社区'])
>>> varDict3=dict(varDict3)
>>> varDict3
{'urlName': 'inotemate.com', 'userCount': 10, 'urlAlais': 'iNoteMate社区'}
- 通过应用dict()函数和zip() 函数,可将前两个列表、元组和字符串转换为对应的字典
>>> keys = ['one', 'two', 'three']
>>> values = [1, 2, 3]
>>> dict(zip(keys,values))
{'one': 1, 'two': 2, 'three': 3}
>>> keys = ('one', 'two', 'three')
>>> values = (1, 2, 3)
>>> dict(zip(keys,values))
{'one': 1, 'two': 2, 'three': 3}
>>> keys="IloveChina"
>>> values="我爱你中华人民共和国"
>>> dict(zip(keys,values))
{'I': '我', 'l': '爱', 'o': '你', 'v': '中', 'e': '华', 'C': '人', 'h': '民', 'i': '共', 'n': '和', 'a': '国'}
注意,无论采用以上哪种方式创建字典,字典中各元素的键都只能是字符串、元组或数字,不能是列表。列表是可变的,不能作为键。
- 如果不为dict()函数传入任何参数,则代表创建一个空的字典,例如:
# 创建空的字典
>>> d=dict()
>>> d
{}
4.4.2 访问字典内的元素
列表和元组是通过下标来访问元素的,而字典不同,字典中的元素是无序的,每个元素的位置都不固定,所以字典也不能像列表和元组那样通过下标来访问元素,也不能采用切片的方式一次性访问多个元素,只能通过键来访问对应的值。
Python访问字典元素的具体语法格式为:
varNameDict[key]
其中,varNameDict 表示字典变量的名称,key 表示键名。注意,键必须是存在的,否则会抛出异常,看代码:
>>> keys="IloveChina"
>>> values="我爱你中华人民共和国"
>>> dict(zip(keys,values))
{'I': '我', 'l': '爱', 'o': '你', 'v': '中', 'e': '华', 'C': '人', 'h': '民', 'i': '共', 'n': '和', 'a': '国'}
>>> chinaDict=dict(zip(keys,values))
>>> chinaDict['I']
'我'
>>> chinaDict['美']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: '美'
除了上面这种方式外,推荐使用dict类型的get()方法来获取指定键对应的值。当指定的键不存在时,get()方法不会抛出异常。get()的语法格式为:
varNameDict.get(key[,default])
其中,varNameDict表示字典变量的名字;key 表示指定的键;default 用于指定要查询的键不存在时,此方法返回的默认值,如果不手动指定,会返回 None。如果想明确地提示使用者该键不存在,那么可以手动设置 get() 的第二个参数,看代码:
>>> chinaDict.get('h')
'民'
>>> chinaDict.get('w') #没有,返回None,交互环境不显示
>>> chinaDict.get('w','没有该键值对应的值') #给出自定义的错误提示信息
'没有该键值对应的值'
>>>
4.4.3 Python删除字典
和删除列表、元组一样,手动删除字典也可以使用 del 关键字,例如:
>>> varNameDict={'id':'51702042005','name':'张三','birthday':'2002-12-14','gender':'male','address':'安徽蚌埠'}
>>> varNameDict
{'id': '51702042005', 'name': '张三', 'birthday': '2002-12-14', 'gender': 'male', 'address': '安徽蚌埠'}
>>> del varNameDict
>>> varNameDict
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'varNameDict' is not defined
Python自带垃圾回收功能,会自动销毁不用的字典,所以一般不需要通过 del来手动删除。
4.4.4 字典内容的基本操作(增删改查键值对)
字典是可变序列,我们可以任意操作字典中的键值对(key-value),常见的字典内容操作有以下几种:
- 向字典中添加新的键值对。
- 修改字典中的键值对。
- 从字典中删除指定的键值对。
- 判断字典中是否存在指定的键值对。
初学者要牢记,字典是由一个一个的key-value构成的见图4-2,key是找到数据的关键,Python对字典的操作都是通过 key 来完成的。
- 向字典添加键值对
向字典添加新的键值对很简单,直接给不存在的key赋值即可,具体语法格式如下:
varNameDict[key] = value
varNameDict 表示字典名称,key表示新的键,value表示新的值,只要是 Python支持的数据类型都行。看代码:
下面代码演示了在现有字典基础上添加新元素的过程:
>>> scoresDict = {'id':'51702042005','高等数学1': 95, '大学英语1': 92, 'C语言': 84,'哲学':'78'} #这是我们大一第一学期的成绩单
>>> scoresDict
{'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78'}
>>> scoresDict['体育']='良好' #添加体育成绩
>>> scoresDict
{'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '良好'}
>>> scoresDict['大学计算机基础']=65 #添加大学计算机基础成绩
>>> scoresDict
{'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '良好', '大学计算机基础': 65}
- 字典修改键值对
字典键key是不能被修改,只能修改值value。字典中各元素的键必须是唯一的,如果新添加元素的键与已存在元素的键相同,那么键所对应的值就会被新的值替换掉,以此达到修改元素值的目的。请看下面的代码:
>>> scoresDict
{'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '良好', '大学计算机基础': 65}
>>> scoresDict['体育']='优秀' #体育成绩错了,改成优秀
>>> scoresDict
{'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> scoresDict['高等数学1']=98 #高数成绩录错了,改成98
>>> scoresDict
{'id': '51702042005', '高等数学1': 98, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
可以看到,字典中没有再添加{'体育':优秀}和{'高等数学1':98}的键值对,而是对原有键值对{'体育':优秀}和{'高等数学1':98}中的value进行了覆盖。
- 字典删除键值对
如果要删除字典中的键值对,还是可以使用del语句。例如:
>>> scoresDict
{'id': '51702042005', '高等数学1': 98, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> del scoresDict['C语言'] #删除C语言成绩
>>> del scoresDict['大学计算机基础'] #删除大学计算机基础成绩
>>> scoresDict
{'id': '51702042005', '高等数学1': 98, '大学英语1': 92, '哲学': '78', '体育': '优秀'}
- 判断字典中是否存在指定键值对
如果要判断字典中是否存在指定键值对,首先应判断字典中是否有对应的键,可以使用 in 或 not in 运算符完成这个操作,对于dict而言,in 或 not in 运算符都是基于key来判断的。看代码:
>>> scoresDict={'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> '哲学' in scoresDict
True
>>> 'Java' in scoresDict
False
通过 in(或 not in)运算符,可以判断出现有字典中是否包含某个键,如果存在,则可以通过键获取对应的值,因此就能判断出字典中是否有指定的键值对。
4.4.5 字典方法
Python字典包含了以下内置函数和方法:
表4-3 字典方法表
|
序号 |
函数及描述 |
|
1 |
dict.clear() |
|
2 |
dict.copy() |
|
3 |
dict.fromkeys() |
|
4 |
dict.get(key, default=None) |
|
5 |
key in dict |
|
6 |
dict.items() |
|
7 |
dict.keys() |
|
8 |
dict.setdefault(key, default=None) |
|
9 |
dict.update(dict2) |
|
10 |
dict.values() |
|
11 |
dict.pop(key[,default]) |
|
12 |
dict.popitem() |
1、keys()、values() 和 items() 方法
将这三个方法放在一起介绍,是因为它们都用来获取字典中的特定数据:
- keys() 方法用于返回字典中的所有键(key);
- values() 方法用于返回字典中所有键对应的值(value);
- items() 用于返回字典中所有的键值对(key-value)。
看下面的代码:
>>> scoresDict={'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> scoresDict.values()
dict_values(['51702042005', 95, 92, 84, '78', '优秀', 65])
>>> scoresDict.keys()
dict_keys(['id', '高等数学1', '大学英语1', 'C语言', '哲学', '体育', '大学计算机基础'])
>>> scoresDict.items()
dict_items([('id', '51702042005'), ('高等数学1', 95), ('大学英语1', 92), ('C语言', 84), ('哲学', '78'), ('体育', '优秀'), ('大学计算机基础', 65)])
可以发现,keys()、values() 和 items() 返回值的类型分别为 dict_keys、dict_values 和 dict_items。
需要注意的是,在Python2.x 中,上面三个方法的返回值都是列表(list)类型。但在Python3.x 中,它们的返回值并不是我们常见的列表或者元组类型,因为Python3.x不希望用户直接操作这几个方法的返回值。
在Python3.x 中如果想使用这三个方法返回的数据,一般有下面两种方案:
- 使用 list() 函数,将它们返回的数据转换成列表,
例如:
>>> scoresDict={'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> list(scoresDict.keys())
['id', '高等数学1', '大学英语1', 'C语言', '哲学', '体育', '大学计算机基础']
- 使用for in循环遍历它们的返回值,
例如:
纯文本复制
scoresDict={'编号': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
for key in scoresDict.keys():
print(key,'\t',end=' ')
print("\n----------------------------------------------------------------")
for value in scoresDict.values():
print(value,'\t',end=" ")
print("\n----------------------------------------------------------------")
for key,value in scoresDict.items():
print("key=",key,"\tvalue=",value)
运行结果为:
编号 高等数学1 大学英语1 C语言 哲学 体育 大学计算机基础
----------------------------------------------------------------
51702042005 95 92 84 78 优秀 65
----------------------------------------------------------------
key= 编号 value= 51702042005
key= 高等数学1 value= 95
key= 大学英语1 value= 92
key= C语言 value= 84
key= 哲学 value= 78
key= 体育 value= 优秀
key= 大学计算机基础 value= 65
2、copy() 方法
copy()方法返回一个字典的拷贝,也即返回一个具有相同键值对的新字典,例如:
>>> scoresDict={'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> nscoreDict=scoresDict.copy()
>>> nscoreDict
{'id': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
copy() 方法将字典scoresDict的数据全部复制给了字典nscoreDict。
注意,copy() 方法所遵循的拷贝原理,既有深拷贝,也有浅拷贝。拿拷贝字典scoresDict为例,copy()方法只会对最外层的键值对进行深拷贝,也就是说,它会再申请一块内存用来存放最外层的数据;如果在字典内部在嵌套序列类型,此方法对其做的就是浅拷贝,也就是说,复制后嵌套的序列类型的数据不是拷贝,只会和原来的字典共享其内容。说的这么绕,我们来举个例子gradeDict:。
>>> gradeDict={'一等奖':[1,2,3],'二等奖':range(4,11),'三等奖':range(11,21),' 优 秀奖':range(21,61)}
>>> bcopy=gradeDict.copy() #复制
>>> bcopy
{'一等奖': [1, 2, 3], '二等奖': range(4, 11), '三等奖': range(11, 21), ' 优秀奖': range(21, 61)}
>>> gradeDict
{'一等奖': [1, 2, 3], '二等奖': range(4, 11), '三等奖': range(11, 21), ' 优秀奖': range(21, 61)} #bcopy和gradeDict内容一致,拷贝成功
>>> bcopy['一等奖'].remove(1) #今年没有第一名,有点诡异
>>> gradeDict #我只改了bcopy的啊,没改gradeDict啊
{'一等奖': [2, 3], '二等奖': range(4, 11), '三等奖': range(11, 21), ' 优秀奖': range(21, 61)}
>>> bcopy #说明,两个变量中的'一等奖'共享[1,2,3]列表
{'一等奖': [2, 3], '二等奖': range(4, 11), '三等奖': range(11, 21), ' 优秀奖': range(21, 61)}
>>> gradeDict['鼓励奖']=range(61,500) #增加一个鼓励奖
>>> bcopy #没有 说面两个变量最外层的数据是在不同内存区域的。
{'一等奖': [2, 3], '二等奖': range(4, 11), '三等奖': range(11, 21), ' 优秀奖': range(21, 61)}
>>> gradeDict #只有嵌套的子序列类型数据是是共享的
{'一等奖': [2, 3], '二等奖': range(4, 11), '三等奖': range(11, 21), ' 优秀奖': range(21, 61), '鼓励奖': range(61, 500)}
注意,执行过程中的文字说明,移除嵌套序列类型数据内容时候发现,嵌套的子序列类型内容是共享的,而最外层的数据是复制的,完全在不同的内存区域。后面的给gradeDict增加一个鼓励奖,bcopy的内容就没有增加。
3、update() 方法
update()方法可以使用一个字典所包含的键值对来更新己有的字典,如果被更新的字典中己包含对应的键值对,那么原value会被覆盖;如果被更新的字典中不包含对应的键值对,则该键值对被添加到现在的字典,还是看代码:
>>> scoresDict={'编号': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84}
>>> s2Dict={'编号': '51702042006','哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> scoresDict
{'编号': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84}
>>> s2Dict
{'编号': '51702042006', '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> scoresDict.update(s2Dict) #使用s2Dict更新scoresDict,注意编号
>>> scoresDict
{'编号': '51702042006', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65} #scoresDict的编号被替换为s2Dict的编号了
>>> s2Dict #s2Dict内容未变
{'编号': '51702042006', '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
从运行结果可以看出,由于被更新的字典中已包含 key 为'编号'的键值对,因此更新时该键值对的value将被改写;而被更新的字典中不包含 key为 '哲学'、 '体育'和 '大学计算机基础'的键值对,所以更新时会为原字典增加三个新的键值对。
4、pop()和 popitem()方法
pop()和 popitem()都用来删除字典中的键值对,不同的是,pop()用来删除指定的键值对,而popitem()用来随机删除一个键值对,因为dict是无序的,从字面意义上理解呢,删除那个元素不能确定,但是在实际的操作过程中,键值对在底层也是有存储顺序的,所以popitem() 总是弹出底层中的最后一个 key-value,这和列表的 pop() 方法类似,都实现了数据结构中“出栈”的操作,它们的语法格式如下:
varNameDict.pop(key)
varNameDict.popitem()
其中,varNameDict表示字典变量的名称,key 表示键。
下面的代码演示popitem()的使用:
>>> scoresDict={'编号': '51702042006', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> scoresDict.popitem()
('大学计算机基础', 65)
>>> scoresDict.popitem()
('体育', '优秀')
>>> scoresDict.popitem()
('哲学', '78')
>>> scoresDict.popitem()
('C语言', 84)
>>> scoresDict.popitem()
('大学英语1', 92)
>>> scoresDict.popitem()
('高等数学1', 95)
>>> scoresDict.popitem()
('编号', '51702042006')
>>> scoresDict.popitem()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'popitem(): dictionary is empty'
>>>
从弹出的顺序看,总是弹出最后一个保存在字典的中的键值对。
我们在看看pop()函数:
>>> scoresDict={'编号': '51702042006', '高等数学1': 95, '大学英语1': 92, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> scoresDict.pop() #至少的有个参数
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: pop expected at least 1 argument, got 0
>>> scoresDict.pop("大学英语1") #如果键值存在,直接弹出其值
92
>>> scoresDict #弹出后,值对被删除
{'编号': '51702042006', '高等数学1': 95, 'C语言': 84, '哲学': '78', '体育': '优秀', '大学计算机基础': 65}
>>> scoresDict.pop("Java") #弹出不存在的key会报错。
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Java'
5、setdefault() 方法
setdefault()方法用来返回某个 key 对应的 value,其语法格式如下:
varNameDict.setdefault(key, defaultvalue)
说明,varNameDict表示字典名称,key表示键,defaultvalue表示默认值(可以不写,不写的话是 None)。当指定的 key不存在时,setdefault() 会先为这个不存在的 key 设置一个默认的 defaultvalue,然后再返回 defaultvalue。
也就是说,setdefault()方法总能返回指定key对应的value:
如果该key存在,那么直接返回该key对应的value;
如果该 key不存在,那么先为该 key设置默认的defaultvalue,然后再返回该key对应的defaultvalue。
请看下面的代码:
>>> scoresDict={'编号': '51702042006', '高等数学1': 95, '大学英语1':92}
>>> scoresDict.setdefault('编号','51702041107')
'51702042006' #'编号' 存在,直接返回其值
>>> scoresDict={'编号': '51702042006', '高等数学1': 95, '大学英语1':92}
>>> scoresDict.setdefault('C语言',98) #没有'C语言',添加,赋值为98
98
>>> scoresDict
{'编号': '51702042006', '高等数学1': 95, '大学英语1': 92, 'C语言': 98}
>>> scoresDict.setdefault("体育") #没有"体育" 赋值为None
>>> scoresDict
{'编号': '51702042006', '高等数学1': 95, '大学英语1': 92, 'C语言': 98, '体育': None}
>>> scoresDict.setdefault("体育","优秀") #有"体育",返回值,不能修改
>>> scoresDict
{'编号': '51702042006', '高等数学1': 95, '大学英语1': 92, 'C语言': 98, '体育': None}
>>> scoresDict.setdefault("哲学","优秀") #没有 "哲学" 增加值对,返回值
'优秀'
4.5 集合
Python的集合类型和数学中的集合概念一样,用来保存不重复的元素,即集合中的元素都是唯一的,互不相同。从形式上看,和字典类似,Python集合的所有元素放在一对大括号{}中,相邻元素之间用“,”分隔,如下所示:
{item1,item2,...,itemn}
其中,itemn 表示集合中的元素,个数没有限制。
从内容上看,同一集合中,只能存储不可变的数据类型,包括整形、浮点型、字符串、元组,无法存储列表、字典、集合这些可变的数据类型,否则Python解释器会抛出 TypeError 错误。比如说:
>>> {{'no':1}}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'dict'
>>> {['x','y','z',4]}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> {{"oliver","kate","Rose"}}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'set'
并且需要注意的是,数据必须保证是唯一的,因为集合对于每种数据元素,只会保留一份。例如:
>>> {1,2,3,5,4,3,5,43,3,2,4,2,(1,2,3),(1,2,3),'name','id','price','id'}
{1, 2, 3, 4, 5, 'price', 43, (1, 2, 3), 'name', 'id'}
由于Python中的set集合是无序的,所以每次输出时元素的排序顺序可能都不相同。
Python的集合类型有两种:一种是set类型的集合,另一种是frozenset 类型的集合。区别是,set 类型集合可以做添加、删除元素的操作,而forzenset类型集合不行。我们先看set类型集合。
4.5.1 Set集合
1、创建set集合
有两种创建set集合的方法,分别是使用{}创建和使用set()函数将列表、元组等类型数据转换为集合。
A、使用{}创建
在Python中,创建set集合可以像列表、元素和字典一样,直接将集合赋值给变量,从而实现创建集合的目的,其语法格式如下:
varNameSet = {item1,item2,...,itemn}
其中,varNameSet表示集合变量的名称,起名时既要符合Python命名规范,也要避免与Python内置函数重名。
比如:
>>> varNameSet={1,2,3,5,4,3,5,43,3,2,4,2,(1,2,3),(1,2,3),'name','id','price','id'}
>>> varNameSet
{1, 2, 3, 4, 5, 'price', 43, (1, 2, 3), 'name', 'id'}
B、set()函数创建集合
set()函数为Python的内置函数,其功能是将字符串、列表、元组、range 对象等可迭代对象转换成集合。该函数的语法格式如下:
varNameSet = set(iterationType)
其中,iterationType就表示字符串、列表、元组、range对象、字典等可迭代的数据。比如:
>>> scoresDict={'编号': '51702042005', '高等数学1': 95, '大学英语1': 92, 'C语言': 84}
>>> varName1Set=set(scoresDict.keys())
>>> varName1Set
{'C语言', '高等数学1', '大学英语1', '编号'}
>>> varName2Set=set(scoresDict.values())
>>> varName2Set
{'51702042005', 92, 84, 95}
>>> str2Set=set("iNoteMate社区")
>>> str2Set
{'M', 'N', '社', 'a', 'e', 'o', 't', 'i', '区'}
>>> list2Set=set([1,3,5,'string'])
>>> list2Set
{1, 'string', 3, 5}
>>> tupple2Set=set((45,'中华人民共和国','首都',45,7764,3,3.5))
>>> tupple2Set
{3, 3.5, '首都', '中华人民共和国', 45, 7764}
>>> range2Set=set(range(101,110))
>>> range2Set
{101, 102, 103, 104, 105, 106, 107, 108, 109}
注意,如果要创建空集合,只能使用 set()函数实现。因为直接使用一对 {},Python解释器会将其视为一个空字典。
2、Python访问set集合元素
集合中的元素是无序的,无法象列表那样使用下标访问元素。Python中,访问集合元素最常用的方法是使用循环结构将集合中的数据逐一读取出来。比如:
>>> varNameSet={1,2,3,5,4,3,5,43,3,2,4,2,(1,2,3),(1,2,3),'name','id','price','id'}
>>> for item in varNameSet:
... print(item,end=' ')
...
1 2 3 4 5 price 43 (1, 2, 3) name id
3、Python删除set集合
和其他序列类型一样,手动函数集合类型,也可以使用del()语句,例如:
>>> varNameSet={1,2,3,5,4,3,5,43,3,2,4,2,(1,2,3),(1,2,3),'name','id','price','id'}
>>> varNameSet
{1, 2, 3, 4, 5, 'price', 43, (1, 2, 3), 'name', 'id'}
>>> del varNameSet
>>> varNameSet
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'varNameSet' is not defined
>>> varNameSet={1,2,3,5,4,3,5,43,3,2,4,2,(1,2,3),(1,2,3),'name','id','price','id'}
>>> varNameSet
{1, 2, 3, 4, 5, 'price', 43, (1, 2, 3), 'name', 'id'}
>>> del(varNameSet)
>>> varNameSet
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'varNameSet' is not defined
4、set集合基本操作(添加、删除、交集、并集、差集)
set集合最常用的操作是向集合中添加、删除元素,以及集合之间做交集、并集、差集等运算。
A、向set集合中添加元素
向set 集合中添加元素,可以使用set类型提供的 add() 方法实现,该方法的语法格式为:
varNameSet.add(item)
其中,varNameSet 表示要添加元素的集合,item表示要添加的元素内容。需要注意的是,使用 add() 方法添加的元素,只能是数字、字符串、元组或者布尔类型(True 和 False)值,不能添加列表、字典、集合这类可变的数据,否则Python解释器会报 TypeError 错误。例如:
>>> varNameSet={1,2,3,5,4,3,5,43,3,2,4,2,(1,2,3),(1,2,3),'name','id','price','id'}
>>> varNameSet
{1, 2, 3, 4, 5, 'price', 43, (1, 2, 3), 'name', 'id'}
>>> varNameSet.add(1)
>>> varNameSet
{1, 2, 3, 4, 5, 'price', 43, (1, 2, 3), 'name', 'id'}
>>> varNameSet.add((1,2))
>>> varNameSet.add(1.4)
>>> varNameSet
{1, 2, 3, 4, 5, 'price', (1, 2), 1.4, 43, (1, 2, 3), 'name', 'id'}
>>> varNameSet.add(False)
>>> varnameSet
>>> varNameSet
{False, 1, 2, 3, 4, 5, 'price', (1, 2), 1.4, 43, (1, 2, 3), 'name', 'id'}
>>> varNameSet.add("中华")
>>> varNameSet
{False, 1, 2, 3, 4, 5, 'price', (1, 2), 1.4, 43, (1, 2, 3), 'name', 'id', '中华'}
B、从set集合中删除元素
删除set集合中的指定元素,可以使用 remove()方法,该方法的语法格式如下:
varNameSet.remove(item)
需要注意的是,如果被删除元素本就不包含在集合中,则此方法会抛出 KeyError 错误,例如:
>>> varNameSet={1,2,3,5,4,3,5,43,3,2,4,2,(1,2,3),(1,2,3),'name','id','price','id'}
>>> varNameSet
{1, 2, 3, 4, 5, 'price', 43, (1, 2, 3), 'name', 'id'}
>>> varNameSet.remove(2)
>>> varNameSet
{1, 3, 4, 5, 'price', 43, (1, 2, 3), 'name', 'id'}
>>> varNameSet.remove(2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 2
上面程序中,由于集合中的元素2已被删除,当再次尝试用remove()方法删除时,会引发KeyError错误。如果我们不想在删除失败时令解释器提示KeyError 错误,还可以使用discard()方法,此方法和remove()方法的用法完全相同,唯一的区别就是,当删除集合中元素失败时,此方法不会抛出任何错误。看代码:
>>> varNameSet={1,2,3,5,4,3,5,43,3,2,4,2,(1,2,3),(1,2,3),'name','id','price','id'}
>>> varNameSet
{1, 2, 3, 4, 5, 'price', 43, (1, 2, 3), 'name', 'id'}
>>> varNameSet.remove('price')
>>> varNameSet
{1, 2, 3, 4, 5, 43, (1, 2, 3), 'name', 'id'}
>>> varNameSet.remove('price')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'price'
>>> varNameSet.discard("price")
>>>
C、Python集合做交集、并集、差集运算
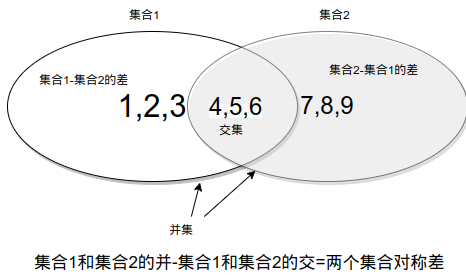
图4-3 集合操作示意图
我们写程序的过程中,用到的集合操作通常是交、并、差以及对称差运算,图4-3中,有2个集合,分别为 aSet={1,2,3,4,5,6} 和 bSet={4,5,7,8,9},它们既有相同的元素,也有不同的元素。数学上的集合运算以及Python中的表示方法如表4-4所示。
表4-4 set集合运算表示及其含义
|
运算操作 |
Python运算符 |
含义 |
|
交集 |
& |
取两集合公共的元素 |
|
并集 |
| |
取两集合全部的元素 |
|
差集 |
- |
取一个集合中另一集合没有的元素 |
|
对称差集 |
^ |
取集合 A 和 B 中不属于 A&B 的元素 |
下面我们以图4-3中的两个集合来演示这四个操作在Python语言中的使用方法,看代码:
>>> aSet={1,2,3,4,5,6}
>>> bSet={4,5,6,7,8,9}
>>> aSet & bSet #交集
{4, 5, 6}
>>> aSet | bSet #并操作
{1, 2, 3, 4, 5, 6, 7, 8, 9}
>>> aSet - bSet #a-b差
{1, 2, 3}
>>> bSet-aSet #b-a差
{8, 9, 7}
>>> aSet ^ bSet #对称差
{1, 2, 3, 7, 8, 9}
- set集合方法
表4-4 set集合方法
|
方法名 |
语法格式 |
功能 |
|
add() |
set1.add() |
向 set1 集合中添加数字、字符串、元组或者布尔类型 |
|
clear() |
set1.clear() |
清空 set1 集合中所有元素 |
|
copy() |
set2 = set1.copy() |
拷贝 set1 集合给 set2 |
|
difference() |
set3 = set1.difference(set2) |
将 set1 中有而 set2 没有的元素给 set3 |
|
difference_update() |
set1.difference_update(set2) |
从 set1 中删除与 set2 相同的元素 |
|
discard() |
set1.discard(elem) |
删除 set1 中的 elem 元素 |
|
intersection() |
set3 = set1.intersection(set2) |
取 set1 和 set2 的交集给 set3 |
|
intersection_update() |
set1.intersection_update(set2) |
取 set1和 set2 的交集,并更新给 set1 |
|
isdisjoint() |
set1.isdisjoint(set2) |
判断 set1 和 set2 是否没有交集,有交集返回 False;没有交集返回 True |
|
issubset() |
set1.issubset(set2) |
判断 set1 是否是 set2 的子集 |
|
issuperset() |
set1.issuperset(set2) |
判断 set2 是否是 set1 的子集 |
|
pop() |
a = set1.pop() |
取 set1 中一个元素,并赋值给 a |
|
remove() |
set1.remove(elem) |
移除 set1 中的 elem 元素 |
|
symmetric_difference() |
set3 = set1.symmetric_difference(set2) |
取 set1 和 set2 中互不相同的元素,给 set3 |
|
symmetric_difference_update() |
set1.symmetric_difference_update(set2) |
取 set1 和 set2 中互不相同的元素,并更新给 set1 |
|
union() |
set3 = set1.union(set2) |
取 set1 和 set2 的并集,赋给 set3 |
|
update() |
set1.update(elem) |
添加列表或集合中的元素到 set1 |
各个方法使用的示例代码如下:
>>> aSet = {1,2,3}
>>> aSet.add((1,2))
>>> aSet
{(1, 2), 1, 2, 3}
>>> aSet = {1,2,3}
>>> aSet.clear()
>>> aSet
set() #set()才表示空集合,{}表示的是空字典
>>> aSet = {1,2,3}
>>> bSet = aSet.copy()
>>> aSet.add(4)
>>> aSet
{1, 2, 3, 4}
>>> aSet
{1, 2, 3}
>>> aSet = {1,2,3}
>>> bSet = {3,4}
>>> set3 = aSet.difference(bSet)
>>> set3
{1, 2}
>>> aSet = {1,2,3}
>>> bSet = {3,4}
>>> aSet.difference_update(bSet)
>>> aSet
{1, 2}
>>> aSet = {1,2,3}
>>> aSet.discard(2)
>>> aSet
{1, 3}
>>> aSet.discard(4)
{1, 3}
>>> aSet = {1,2,3}
>>> bSet = {3,4}
>>> set3 = aSet.intersection(bSet)
>>> set3
{3}
>>> aSet = {1,2,3}
>>> bSet = {3,4}
>>> aSet.intersection_update(bSet)
>>> aSet
{3}
>>> aSet = {1,2,3}
>>> bSet = {3,4}
>>> aSet.isdisjoint(bSet)
FALSE
>>> aSet = {1,2,3}
>>> bSet = {1,2}
>>> aSet.issubset(bSet)
FALSE
>>> aSet = {1,2,3}
>>> bSet = {1,2}
>>> aSet.issuperset(bSet)
TRUE
>>> aSet = {1,2,3}
>>> a = aSet.pop()
>>> aSet
{2,3}
>>> a
1
>>> aSet = {1,2,3}
>>> aSet.remove(2)
>>> aSet
{1, 3}
>>> aSet.remove(4)
Traceback (most recent call last):
File <pyshell#90>, line 1, in <module>
aSet.remove(4)
KeyError: 4
>>> aSet = {1,2,3}
>>> bSet = {3,4}
>>> set3 = aSet.symmetric_difference(bSet)
>>> set3
{1, 2, 4}
>>> aSet = {1,2,3}
>>> bSet = {3,4}
>>> aSet.symmetric_difference_update(bSet)
>>> aSet
{1, 2, 4}
>>> aSet = {1,2,3}
>>> bSet = {3,4}
>>> set3=aSet.union(bSet)
>>> set3
{1, 2, 3, 4}
>>> aSet = {1,2,3}
>>> aSet.update([3,4])
>>> aSet
{1,2,3,4}
4.5.2 frozenset集合
set 集合是可变序列,程序可以改变序列中的元素;frozenset 集合是不可变序列,程序不能改变序列中的元素。set 集合中所有能改变集合本身的方法,比如 remove()、discard()、add() 等,frozenset 都不支持;set 集合中不改变集合本身的方法,fronzenset 都支持。
我们可以在交互式编程环境中输入dir(frozenset)来查看 frozenset 集合支持的方法:
>>> dir(frozenset)
['__and__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__rand__', '__reduce__', '__reduce_ex__', '__repr__', '__ror__', '__rsub__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__xor__', 'copy', 'difference', 'intersection', 'isdisjoint', 'issubset', 'issuperset', 'symmetric_difference', 'union']
现在可以改变集合内容的方法这里都没有,如果你不确定,可以看看两个类型的方法的对比:
>>> dir(set)
['__and__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__iand__', '__init__', '__init_subclass__', '__ior__', '__isub__', '__iter__', '__ixor__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__rand__', '__reduce__', '__reduce_ex__', '__repr__', '__ror__', '__rsub__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__xor__', 'add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
现在多了修改集合内容的方法。frozenset 集合的这些方法和set集合中同名方法的功能是一样的。两种情况下可以使用 fronzenset:
- 当集合元素不需要改变时,可以使用fronzenset替代set,这样更安全。
- 程序要求必须是不可变对象,这时也要使用fronzenset替代set。比如,字典(dict)的键(key)就要求是不可变对象。
我们来看看那frozenset 的用法:
>>> aSet={1,2,3,4,5,6}
>>> aSet
{1, 2, 3, 4, 5, 6}
>>> bSet=frozenset(range(4,10))
>>> bSet
frozenset({4, 5, 6, 7, 8, 9})
>>> cSet={100,101}
>>> aSet.add(bSet)
>>> aSet
{1, 2, 3, 4, 5, 6, frozenset({4, 5, 6, 7, 8, 9})}
>>> aSet.add(cSet)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'set'
需要注意的是,set集合本身的元素必须是不可变的, 所以set的元素不能是set,只能是frozenset。 aSet.add(bSet)向set中添加 frozenset 是没问题的,因为bSet是frozenset,是不可变的;但是,aSet.add(cSet)中尝试向set中添加cSet,这是不允许的,因为cSet是set类型,是可变的。
4.6 游戏时间-背单词
我们利用前面学过的基本Python知识来构建一个命令行版的背单词软件,主要目的是综合利用前面学过的东西,背单词要求实现以下功能:
- 可以手工添加新词,格式为 英语:中文
- 可以根据英文查找中文的意思,也可以根据中文查找有没有符合意思的英文。
- 背单词的时候随机出现单词,每次出现的数量由使用者自己决定。
- 统计使用着每次背单词的正确率。
4.6.1 程序设计思路
这个程序的核心显然中英文单词成对存储,还有个默认的特性我们应该知道,在存储单词对的时候,英文是不会重复出现的,而中文单词时可能重复出现的,根据这个特性,我们想到一个天然契合的序列类型:字典,英文单词作为Key,中文意思作为value,我们所有功能都是围绕着这个字典结构来实现。
- 添加单词,是向字典内添加键值对。
- 根据英文查找中文的意思,使用的是get方法每,如果有对应的中文意思就返回,如果没有,就返回None
- 通过中文查找英文就有点麻烦,只能通过循环遍历value,查看value是不是和中文单词一样或者近似,如果是添加到结果中,因为,同一个中文可能会对应多个英文单词。
- 背单词随机出现,使用random模块进行,可以使用choice,也可以直接shuffle取其中的一段。
- 正确的统计,就是定一个变量记录正确的个数。
4.6.2 程序实现
import random as t
wordDict = {"easy": "容易", "difficult": "困难", "answer": "回答", "continue": "继续", "blue": "蓝色"}
while True:
print("""
欢迎来到背单词
根据英文单词回答汉语或者根据汉语回答英文单词
-------------------------------------------
1.英语——>汉语
2.汉语——>英语
3.单词列表
4.添加新词对
5.退出系统
""")
a = int(input("\n\n\n\选择需要进行的操作(1、2、3、4、5):"))
if (a == 1):
n = 0
m = 0
iscontinue = "y"
count=0
while (iscontinue.upper() == "Y" and count<5):
count=count+1
print("第",count,"轮")
enWord = t.choice(list(wordDict.keys()))
print("随机生成在单词:")
print(">------> " + enWord)
guess = input("\n输入汉语: ").strip() # 防止用户误操作录入空白
if guess != wordDict[enWord]:
print("对不起,不正确。")
n = n + 1
print('\n——>正确率:%.2f' % (m / (n + m)))
else:
print("真棒!答对了!!")
m = m + 1
print('\n——>正确率:%.2f' % (m / (n + m)))
iscontinue = input("\n\n是否继续(Y/N):")
elif a == 2:
n = 0;
m = 0;
enWord = []
iscontinue = "y"
count=0
while (iscontinue.upper() == "Y" and count< 5):
count=count+1
print("第",count,"轮")
zhWord = t.choice(list(wordDict.values()))
print("随机生成在汉语:")
print(">------> " + zhWord)
guess = input("\n输入英语: ").strip()
for key, value in wordDict.items():
if zhWord == value:
enWord.append(key)
print(enWord)
if guess not in enWord:
print("对不起,不正确。")
n = n + 1
print('\n——>正确率:%.2f' % (m / (n + m)))
else:
print("真棒!答对了!!")
m = m + 1
print('\n——>正确率:%.2f' % (m / (n + m)))
iscontinue = input("\n\n是否继续(Y/N):")
elif a == 3:
print("************************")
print("\n")
for key, value in wordDict.items():
print(key, " ", value, "\n")
print("\n")
print("************************")
a = input("输入5背诵单词结束,其他任意键继续!——>: ")
elif a == 4:
iscontinue = "y"
print("向字典加入新词!请先输入英文单词,然后在输入中文解释!")
while iscontinue.upper() == "Y":
enKeyStr=input("请输入英文单词:").strip()
zhValueStr=input("请输入英文单词的中文解释:").strip()
wordDict[enKeyStr]=zhValueStr
iscontinue=input("\n\n是否继续添加新词(Y/N):")
elif a==5:
exit()
else:
print("输入格式错误,重新输入!!")
0 条 查看最新 评论
没有评论